Artículo publicado por David L. Chandler el 9 de febrero de 2012 en MIT News
¿Cómo saber cuándo es significativo un nuevo hallazgo? El valor sigma puede decírtelo – pero cuidado con los peces muertos.
Es una cuestión que surge con virtualmente cada gran nuevo hallazgo en ciencia o medicina: ¿Qué hace que un resultado sea lo bastante fiable como para tomarse en serio? La respuesta tiene que ver con su significado estadístico – pero también con los juicios sobre qué estándares tienen sentido en una situación dada.
La unidad de medida que se ofrece normalmente cuando se habla de significado estadístico es la desviación estándar, expresada con la letra griega minúscula sigma (σ). El término se refiere a la cantidad de variabilidad en un conjunto de datos dado: si los datos apuntan todos a una zona conjunta o están muy dispersos.
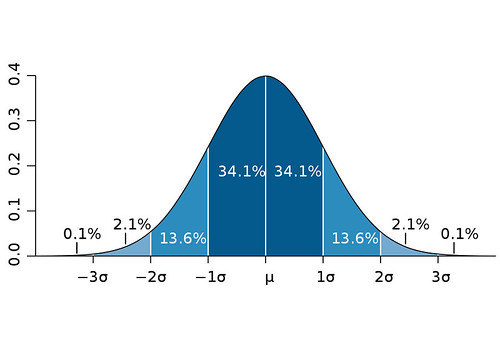
Distribución normal
En muchas situaciones, los resultados de un experimento siguen lo que se conoce como “distribución normal”. Por ejemplo, si lanzas una moneda 100 veces y cuentas cuántas veces sale cara, el resultado medio será 50 veces. Pero si realizas esta prueba 100 veces, la mayor parte de los resultados estará cerca de 50, pero no será exactamente ese valor. Tendrás casi los mismos casos de 49 ó 51. También tendrás unos pocos de 45 o 55, pero casi ninguno de 20 o de 80. Si dibujas las 100 pruebas en una gráfica, tendrás una forma bien conocida llamada curva de campana, que es más alta en el medio y más baja en los extremos. Ésto es una distribución normal.
La desviación es lo lejos que está un punto dado respecto a la media. En el ejemplo de la moneda, un resultado de 47 tiene una desviación de tres respecto al valor medio de 50. La desviación estándar es la raíz cuadrada de la media de todas las desviaciones al cuadrado. Una desviación estándar, o un sigma, dibujado por encima o debajo del valor medio en tal curva de distribución normal, definiría una región que incluye el 68 por ciento de todos los puntos de datos. Dos sigmas por encima o debajo incluirían aproximadamente un 95 por ciento de los datos, y tres sigmas el 99,7 por ciento.
Entonces, ¿cuándo un punto de datos concreto – o resultado de investigación – se considera significativo? La desviación estándar puede ofrecernos una regla: Si un punto de datos está a unas pocas desviaciones estándar del modelo que se está poniendo a prueba, ésto es una prueba sólida de que dicho punto de datos no es consistente con el modelo. Sin embargo, cómo usar esta regla depende de la situación. John Tsitsiklis, Profesor Clarence J. Lebel de Ingeniería Eléctrica en el MIT, que enseña el curso de Fundamentos de Probabilidad, dice que: “la estadística es un arte, con mucho espacio para la creatividad y los errores”. Parte del arte consiste en decidir qué medidas tienen sentido para una configuración dada.
Por ejemplo, si estás haciendo una encuesta sobre cuánta gente planea votar en unas elecciones, la convención aceptada es de dos desviaciones estándar por encima o debajo de la media, lo cual da un nivel de confianza del 95 por ciento, lo que es razonable. El intervalo de dos sigmas es a lo que los encuestadores se refieren cuando dicen “el margen de error de la muestra”, como un 3 por ciento, en sus conclusiones.
Esto significa que si preguntas a toda la población y obtienes un resultado concreto, y haces la misma pregunta a un grupo aleatorio de 1000 personas, hay un 95 por ciento de posibilidades de que los resultados del segundo grupo estén a dos sigma de los resultados del primero. Si una encuesta encuentra que el 55 por ciento de toda la población está a favor del candidato A, entonces el 95 por ciento de las veces, los resultados de la segunda encuesta estarán en algún punto entre el 52 y el 58 por ciento.
Por supuesto, esto también significa que el 5 por ciento de las veces, el resultado estaría fuera del rango de dos sigmas. Este grado de incertidumbre está bien para una encuesta de opinión, pero puede que no para el resultado de un crucial experimento que desafía la comprensión de los científicos sobre un importante fenómeno – como el anuncio del pasado otoño de la detección de neutrinos que se movían más rápido que la velocidad de la luz en un experimento del Centro Europeo de Investigación Nuclear (CERN).
Seis sigmas pueden estar equivocadas
Técnicamente, los resultados de ese experimento tenían un nivel de confianza muy alto: seis sigmas. En la mayor parte de casos, un resultado de cinco sigmas se considera como el estándar de significación, que corresponde aproximadamente a una posibilidad en un millón de que los hallazgos sean sólo el resultado de variaciones aleatorias: seis sigmas se traduce como una posibilidad entre 500 millones de que el resultado sea una fluctuación aleatoria. (Una estrategia común de gestión de negocios conocida como “Seis Sigma” se deriva a partir de este término, y se basa en instaurar procedimientos rigurosos de control de calidad para reducir los residuos).
Pero en ese experimento del CERN, el cual tenía el potencial de dar un vuelco a un siglo de física aceptada y confirmada en miles de pruebas de distintos tipos, aún no es lo bastante bueno. Por una razón, asume que los investigadores han realizado el análisis correctamente y no han pasado por alto alguna fuente de error sistemático. Y debido a que los resultados son tan inesperados y revolucionarios, esto es exactamente lo que la mayoría de físicos creen que ha pasado – alguna fuente de error no detectada.
Es interesante señalar que un conjunto de resultados distinto procedente del mismo acelerador de partículas del CERN se interpretó de manera bastante diferente.
También se anunció el año pasado una posible detección de algo llamado bosón de Higgs – una partícula subatómica teórica que ayudaría a explicar por qué las partículas tienen masa . Este resultado tenía sólo un nivel de confianza de 2,3 sigmas, correspondiente a, aproximadamente, una posibilidad entre 50 de que el resultado fuese un error aleatorio (nivel de confianza del 98 por ciento). Debido a que encaja con lo esperado, basándonos en la física actual, la mayor parte de físicos cree que el resultado probablemente es correcto, a pesar de que su nivel de confianza estadística es mucho menor.
Significativo pero falso
Pero se complica más en otras áreas. “Donde el tema se pone realmente complicado es en las ciencias sociales y en la ciencia médica”, dice Tsitsiklis. Por ejemplo, un artículo de 2005 muy citado y publicado en Public Library of Science – titulado “Why most published research findings are wrong” (Por qué la mayor parte de las conclusiones de investigación publicadas son incorrectas) — daba un análisis detallado de una variedad de factores que podrían llevar a conclusiones injustificadas. Sin embargo, esto no se tiene en cuenta en las medidas estadísticas usadas normalmente, incluyendo el “significado estadístico”.
El artículo señala que al observar grandes conjuntos de datos de formas lo bastante diferentes, es fácil encontrar ejemplos que pasen los criterios habituales de significado estadístico, incluso aunque sean realmente simples variaciones aleatorias. ¿Recuerdas el ejemplo de la encuesta, donde una vez de cada 20 un resultado cae aleatoriamente fuera de los límites “significativos”? Bueno, incluso con un nivel de significación de cinco sigmas, si un ordenador genera millones de posibilidades, se descubrirán patrones totalmente aleatorios que encajen con esos criterios. Cuando esto sucede, “no publicas aquellos que no pasan” el test de significación, dice Tsitsiklis, pero algunas correlaciones aleatorias tendrán la apariencia de ser hallazgos reales – “por lo que finalmente terminarás publicando los errores estadísticos.
Un ejemplo de ésto: Muchos artículos publicados en la última década han afirmado encontrar correlaciones significativas entre cierto tipo de comportamientos o procesos mentales y las imágenes cerebrales captadas en imágenes de resonancia magnética, o IRM. Pero a veces estas pruebas pueden encontrar correlaciones aparentes que simplemente son el resultado de fluctuaciones naturales, o “ruido”, en el sistema. Un investigador en 2009 duplicó uno de dichos experimentos, sobre el reconocimiento de expresiones faciales, sólo que en lugar de sujetos humanos escaneó un pez muerto – y encontró resultados “significativos”.
“Si miras en suficientes lugares, puedes tener un resultado de ‘pez muerto’”, dice Tsitsiklis. Inversamente, en muchos casos un resultado con un bajo significado estadístico puede, sin embargo, “decirte algo que merezca la pena investigar”, comenta.
Así que ten en mente que simplemente porque algo encaje con la definición aceptada de “significativo”, no implica necesariamente que lo sea. Todo depende del contexto.
Autor: David L. Chandler
Fecha Original: 9 de febrero de 2012
Enlace Original
No hay comentarios:
Publicar un comentario